Dentro de análise de dados, outliers, ou valores discrepantes, são um conceito fundamental que todo profissional da área de dados deve dominar.
São valores que podem mostrar informações valiosas sobre o conjunto de dados, porém também podem ser muito perigosos para suas análises.
Neste artigo mostraremos de forma prática e teórica como é a influência de um outlier dentro de uma base de dados, além de sugerir conteúdos complementares para maior aprofundamento no assunto.
O que são outliers?
Outliers são pontos discrepantes dos demais dados, ou seja, que se afastam significativamente do padrão observado na maior parte dos dados.
Por exemplo, é um valor que vai se distanciar muito da média geral dos outros, tanto para baixo, quanto para cima.
Se temos por exemplo 10 idades, todas variando entre 17 e 25, porém uma delas é de 90 anos, poderíamos considerar o valor de 90 como um outlier.
E por que isso poderia ser um problema? Bom, vamos para um exemplo utilizando média:
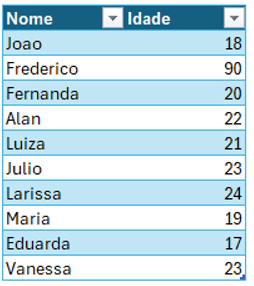
Temos a base de dados acima, vamos tomar como premissa de que queremos saber a média de idade dos alunos dentro de uma sala de aula de uma faculdade.
Se tirarmos a média chegaremos a um valor aproximado de 27 anos. Porém, ao passar o olho na base de dados nota-se que não tem alunos nessa faixa, isso ocorre porque o valor 90 está “puxando” a média para cima.
Ao retirar o valor 90 e refazer a média teremos um valor aproximado de 20 anos, que condiz muito mais com as idades reais dos alunos.
Mas qual de fato seria o problema disso? Bom, imagine um contexto em que queremos saber em qual faixa de idade encontra-se nosso público-alvo, estimar que seja entre pessoas de 27 anos poderia atrair menos alunos do que entre pessoas de 20 anos.
Claro que no exemplo mostrado, a diferença pode não ser tão grande assim, porém em grande quantidade os outliers podem mudar totalmente uma análise de dados, é por isso que aprenderemos a interpretar eles e qual a melhor forma de lidar com situações em que aparecem.
A importância dos Outliers na Análise de dados
Dentro de análise de dados, temos diversas técnicas que vão desde estatística descritiva até modelos complexos de machine learning.
Diante disso, os outliers, quando não identificados e/ou tratados corretamente, podem prejudicar a interpretação dos resultados das técnicas mencionadas e de muitas outras.
Contudo, em muitos casos estes mesmos outliers podem conter informações cruciais sobre o comportamento dos dados.
Por exemplo, imagine um e-commerce de calçados, ele costuma vender em média R$10.000,00 por semana. Porém, em um único dia ele acaba vendendo os mesmos R$10.000,00 que normalmente levariam 1 semana.
Nesse contexto, poderia indicar uma promoção que deu muito certo ou um erro no sistema de registro, dentre diversos outros erros.
Por esse fator o entendimento do outlier torna-se crucial para uma tomada de decisão bem fundamentada em dados reais e precisos.
Como identificar outliers?
Certo, já entendemos o que são os outliers e qual a sua importância no dia a dia de uma empresa ou de um analista. Agora, vamos adentrar nas melhores maneiras de se identificar eles.
Método da caixa (Boxplot)
É uma representação gráfica que é basicamente um modo rápido de se visualizar a distribuição dos dados.
Ele é dividido em Quartis, mediana e os possíveis outliers.
Valores que se encontram fora do intervalo interquartil (IQR) multiplicado por um fator (geralmente 1.5) são considerados outliers.
Para um maior entendimento vamos utilizar o mesmo exemplo dos alunos, porém agora com a representação gráfica de um boxplot:
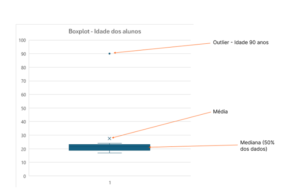
Na primeira seta vermelha temos uma única bolinha, ela representa o valor discrepante (outlier) do nosso conjunto de dados.
Observe a diferença entre a média e mediana (2° e 3° seta). Isso pode ocorrer ou por conta de um alto desvio padrão entre os dados (que vai influenciar no valor da média) ou, como no caso do exemplo, outliers, que também afetam a média.
Agora vamos para um exemplo sem os outliers para conseguirmos visualizar melhor o que de fato cada parte do boxplot representa:
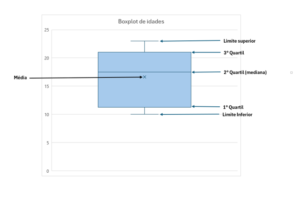
Caso você não saiba o que são quartis, considere que, cada quartil representa ¼ ou seja, 25% dos dados.
Diante disso, temos a seguinte interpretação, do limite inferior ao primeiro quartil ficam 25% de concentração dos dados. Do primeiro quartil ao 2° (também conhecido como mediana) fica mais 25% de concentração completando 50%, e assim por diante.
E, como você já deve estar imaginando, os outliers ficam fora dessas porcentagens de concentração por serem justamente valores isolados e muito acima ou muito abaixo dos demais.
Z-score
Partindo agora para uma representação estatística para identificar um outlier, temos o método z-score.
Este método basicamente mede o número de desvios padrão que um valor se encontra da média.
Fórmula:

Z = pontuação padrão
X = valor observado
μ = média da amostra
σ = desvio padrão da amostra
Não se assuste com a fórmula, hoje temos diversas ferramentas que fazem cálculos estatísticos de maneira prática e rápida.
Para não estender muito no artigo, deixaremos o link de um vídeo que explica como utilizar esse método no Excel: https://www.youtube.com/watch?v=xVjskQvK5to.
A interpretação do valor que essa fórmula vai retornar é bem simples.
Se Z > 3 ou Z < -3, o valor em questão vai se tratar de um outlier.
Como tratar outliers?
Agora que aprendemos como identificar os outliers precisamos saber também como tratá-los.
Algo importante a se mencionar é que, se você é um analista de dados, é sempre interessante ao identificar um valor discrepante, comunicar com alguém que tenha maior conhecimento de negócio, pois essa pessoa vai saber te instruir da melhor forma possível.
Vamos agora explorar algumas abordagens.
Remoção
Caso o outlier seja um erro ou dado incorreto, remover ele pode ser a melhor opção, porém sempre tomando cuidado para não remover algo sem uma boa razão aparente.
Transformação
Fazer transformações matemáticas dos dados, como logaritmos ou normalizações, pode ser muito interessante, uma vez que é uma forma de trazer os dados para uma escala comparável.
Esse método é especialmente útil em algoritmos de machine learning sensíveis a outliers, como a regressão logística.
Análise separada
Alguns outliers podem ser tão importantes para a análise que mereçam uma atenção especial. Nesse caso, você pode fazer uma análise separada detalhada deles.
Tornando possível a identificação de fraudes, falhas de equipamentos, dentre diversos outros problemas.
Impacto dos outliers em modelos de machine learning
Modelos como regressão logística são particularmente sensíveis a outliers, uma vez que eles podem desviar a linha de regressão e comprometer a previsão e precisão do modelo.
Essa é uma das razões pela qual a etapa de análise exploratória dos dados se faz tão importante no início de todo o processo, tornando possível a identificação e tratamento de outliers e garantindo assim que o modelo seja preciso e confiável.
Conclusão
Os outliers desempenham um papel crucial na análise de dados.
Eles podem ser tanto um obstáculo quanto uma oportunidade, a depender de como são tratados.
Ignorar ou não lidar adequadamente com eles pode levar a análises imprecisas, enquanto um tratamento correto pode relevar insights valiosos ou identificação de problemas maiores (como fraude e falha de equipamento mencionado anteriormente).
Ao utilizar métodos estatísticos e ferramentas gráficas para identificá-los e abordá-los adequadamente, você passa a ter análises mais precisas e robustas para a tomada de decisões.
Para mais conteúdos como este, acesse nosso site – https://perspectivadosdados.com
Indicações para maior aprofundamento no assunto
Caso você queira se aprofundar ainda mais no assunto em questão, aqui vão algumas indicações de conteúdos:
Livro Estatística Prática para cientistas de dados – Peter Bruce & Andrew Bruce. https://amzn.to/3Ul4iE3
Livro Estatística de Charles J. Wheelan – https://amzn.to/4dZbigZ

