A análise exploratória de dados (também conhecida como EDA) é uma área relativamente nova, antes, a estatística era muito direcionada a técnicas de inferência.
O campo da análise exploratória surgiu no livro de Tukey, Exploratory Data Analysis em 1977.
Com o passar dos anos, foram surgindo novas ferramentas, tecnologias e elas revolucionaram a forma como a análise exploratória é feita.
No artigo de hoje iremos explorar os principais conceitos da análise e sua importância no mundo dos dados.
Sirva-se com seu cafezinho ou chá, e vamos para mais uma rodada de conhecimento!
Termos fundamentais para tipos de dados
Para darmos prosseguimento com o assunto é fundamental que você entenda quais são os tipos de dados.
Contínuos: assumem qualquer valor em um intervalo (strings, inteiros…);
Discretos: assumem apenas valores inteiros (1, 2, 3…);
Categóricos: recebe um conjunto específico de valores que representam um significado (“sim” e “não”);
Binários: Caso especial de dados categóricos que costumam ser representados de forma numérica ou booleana (1 = “sim”, 0 = “não”);
A importância da análise exploratória
Ela é fundamental para identificação de padrões, anomalias, entender os dados e como eles estão se comportando naquele contexto.
Vamos para um exemplo:
Você enquanto analista precisa identificar dentro da sua base a tipagem dos seus dados.
Isso vai te direcionar em quais técnicas se aplicam melhor para cada dado, além é claro de te ajudar a entender o comportamento da sua base.
Pense, não teria como utilizar medidas resumo como média, mediana e desvio padrão em dados de texto.
É muito comum que dados de números inteiros sejam salvos como strings por exemplo, e sem a etapa da análise exploratória isso poderia passar despercebido, causando erros e problemas posteriores.
Como de fato fazer uma análise exploratória?
Bom, agora que entendemos os termos fundamentais e a sua importância, vamos de maneira prática entender como de fato fazer essa análise.
A escolha da ferramenta
Hoje, temos uma variedade imensa de ferramentas para análise de dados, como Python, Excel, R, Power BI.
Em todas elas, você consegue fazer esse processo, cada uma é claro, com suas particularidades, vantagens e desvantagens.
Escolha a ferramenta que você se sentir mais confortável e aprenda as técnicas corretas (que serão apresentadas agora) que é isso que de fato faz uma análise ter valor real.
Técnicas de estatística descritiva
Para uma boa análise é indicado que você use de técnicas de estatística descritiva, vamos aos exemplos:
Tabelas de frequência
Extremamente úteis para fazer o resumo de um conjunto de dados.
Dentro delas entra a frequência absoluta: quantidade de vezes que o valor de uma variável ocorre em um conjunto.
Frequência relativa: mostra em porcentagem a quantidade de vezes que cada valor ocorreu.
Frequência acumulada: é ela quem vai mostrar a soma das relativas até determinado valor do conjunto de dados.
Exemplo visual de uma tabela de frequência:
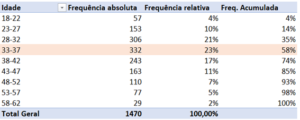
Observe que interessante, com uma simples tabela de frequência somos capazes de identificar qual foi a faixa etária da tabela que tem o maior número de pessoas.
Já logo no começo de uma análise exploratória somos capazes de perceber por exemplo qual faixa etária tem maior predominância de vendas em um comércio.
Gráficos
O ser humano é naturalmente visual, representar números em forma de gráficos pode ser fundamental para um bom entendimento dos dados.
Diante disso, podemos perceber a importância de um gráfico dentro da análise exploratória.
Temos variados tipos de gráficos, cada um se encaixa melhor em um contexto.
Vamos para um exemplo:
Temos uma empresa de perfume e queremos representar visualmente qual o gênero que mais compra em nossa loja.
Nesse contexto, para variáveis categóricas de no máximo 4 (para evitar um gráfico muito poluído) poderíamos utilizar o gráfico de pizza ou de rosca.
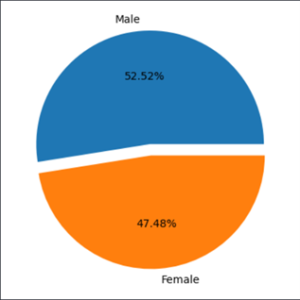
Com uma simples representação visual somos capazes de identificar que a maior parte do público nesse caso é masculino.
Medidas resumo
Outra técnica muito importante para a análise exploratória são as medidas resumos.
Suas principais utilidades são:
- Resumir um conjunto de dados.
- Comparar grupos diferentes.
São divididas em medidas de posição (média, mínimo, máximo, moda, mediana, quartis) e medidas de dispersão (variância, desvio padrão).
Nesse sentido, vale ressaltar que, uma ÚNICA medida resumo não resume adequadamente o conjunto de dados.
Vamos para um exemplo:
A média, como vimos em um artigo anterior, é muito influenciável por outliers, caso tenhamos valores muito altos eles podem puxar a média para cima.
Em conclusão, é interessante utilizar-se da mediana (que pega exatamente o ponto central dos dados) e desvio padrão (para entender o quanto esses dados estão variando entre si).
Análise de correlação
Saindo das análises uni variadas, entramos agora nas análises bidimensionais.
Então, é aqui que somos capazes de observar como uma variável influencia a outra.
Para isso temos gráficos de dispersão (scatter plot):
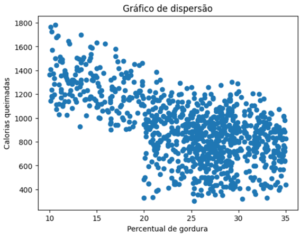
Como podemos interpretar o gráfico acima, perceba que, a medida que o percentual de gordura aumenta (eixo x), as calorias queimadas diminuem (eixo y).
Nesse sentido, esse é um bom exemplo de análise de correlação, com isso podemos observar o comportamento de mais de 1 variável em relação a outra.
Em breve teremos um artigo detalhado sobre interpretação gráfica, onde nos aprofundaremos bem mais sobre cada tipo de gráfico.
Ainda dentro da análise de correlação também temos técnicas como a correlação de Pearson, Information Value (IV), coeficiente de determinação (r²).
Todavia, para que esse artigo não fique muito extenso e fuja do objetivo central que é a análise exploratória, não vamos nos aprofundar muito em cada uma dessas técnicas, porém teremos ainda essa semana (confira no site se já está no ar) tanto a interpretação gráfica quanto as técnicas de correlação.
Assim também, uma importante observação sobre correlação é observar sempre o fator CORRELAÇÃO X CAUSALIDADE.
Basicamente, correlação é uma dependência, associação ou separação de duas variáveis.
Porém, duas variáveis correlacionadas não necessariamente causam uma à outra.
Não é porque uma variável A e uma variável B possuem uma correlação que uma está CAUSANDO a outra.
Temos muitas técnicas como a regressão logística que vão nos ajudar a medir essa causalidade.
Em conclusão, busque sempre fortes evidências de causalidade, não assuma correlação sem antes uma boa e aprofundada análise.
Conclusão
Muito obrigado pela sua leitura até aqui, esperamos ter agregado de alguma forma ao seu conhecimento, abaixo deixaremos algumas recomendações de estudos complementares caso queira se aprofundar.
Lembre-se sempre de fazer uma boa análise exploratória dos seus dados para conseguir identificar padrões, correlações e ter um melhor direcionamento de onde prosseguir com as análises.
Agradecemos imensamente a leitura, lembre-se de conferir nossos conteúdos em https://perspectivadosdados.com/, trazemos todos os dias novos conteúdos sobre análise de dados, economia e finanças!
Indicações de conteúdo:
Estatística prática para cientistas de dados: https://amzn.to/3Cerk9w
Estatística: https://amzn.to/3YOgwHY

